
- Machine and Software Information
- Handling Low Resolution Noisy Images
- Mathematical concepts of Interpolation
- OpenCV Implementation
- Conclusion
Extracting text from images using Optical Character Recognition (OCR) has enormous applications across almost all industries. A robust, scalable OCR solution is an integral part to the digital transformation journey of every organization. These solutions can help an organization to obtain a significant edge over its competitors. For example, OCR solutions can
- Help to reduce the time required in processing paper forms.
- They can digitize information from old important records that can be easily looked up for reference or can be analyzed to build insightful data models.
- Finally, OCR can be used along with images and videos to extract important textual information.
Tesseract is one of the most important opensource OCR engines available today. At the time of writing this blog, Tesseract can extract text on more than 100 languages. The latest tesseract stable version (4.1.1) encompasses a prebuilt OCR engine built upon long short term memory (LSTM) based neural network models. These models can extract text in many real world datasets. However, in case of images that suffer from poor quality, extracting text with high accuracy requires improving image quality using advanced image processing algorithms.
OpenCV is a great opensource tool that is built on C++ with python bindings that can help you develop and apply various advanced image processing algorithms. In the context of text extraction, some of the important image processing approaches include,
- Correcting the text orientation (deskewing).
- Improve the character borders. This can be achieved by converting the image to grayscale and thresholding.
- Increasing the contrast of the image. This can typically be achieved by histogram equalization that converts a normal distribution of pixel intensities to uniform distribution.
- Denoising and smoothening of the images using interpolation algorithms.
I have been working over the past few weeks on using OCR to extract text from images. In this article, I will restrict the discussion to denoising the images.
Machine and Software Information
- Local Machine: Windows 10
- Tesseract Version: v5.0.0-alpha.20200328
- Python Version: 3.7.3
- OpenCV Version: 4.3.0.36
Handling Low Resolution Noisy Images
Consider the following image from which text needs to be extracted

Although, the image section has low resolution (15, 45) and is very noisy, a human eye can clearly see the number present as 166.3. This is possible, because we are able to interpolate the signal between the pixels. However, the prebuilt OCR models in tesseract is unable to perform this interpolation. For example, if we pass this image to pytesseract (the python bindings of tesseract) and use the following standard configs, it does not return any text.
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
custom_config = r'-c tessedit_char_whitelist=0123456789. --oem 3 --psm 6 outputbase digits'
print(pytesseract.image_to_string(img_bbox, config=custom_config))
One way to overcome this problem is to denoise and smoothen the image. We can accomplish this by resampling to improve the pixel density. The new pixel values are interpolated from existing signal values.
Mathematical concepts of Interpolation
This section discusses about the mathematical concepts of interpolation. If you are only interested in applications, feel free to skip this section. In most interpolations, to resample at new we apply a discrete convolution operation on the input signal (here image pixels) with a kernel operator.
\[S(x) = \sum_{i=-a}^{a}f(i)g(x-i)\]Where \(a\) is the region around the current signal point that determines the size of the kernel. There are various types of kernels used to perform such interpolations namely (i) box kernel, (ii) Gaussian kernel etc. However, one of the most important and effective kernels in providing a smooth interpolation of images is the Lanczos kernel \(L(x)\) which is defined as follows
\[L(x) = \begin{cases} 1 & \text{if}\ x = 0, \\ \dfrac{a \sin(\pi x) \sin(\pi x / a)}{\pi^2 x^2} & \text{if}\ -a \leq x < a \ \text{and}\ x \neq 0, \\ 0 & \text{otherwise}. \end{cases}\]The a value is a parameter that is a positive integer which determines the size of the Kernel. Restricting the Kernel size to a fixed constant value ensures that the interpolation operation is an \(O\)(N) operation, where N is the number of signal points to be sampled. The Lanczos kernel is built from the normalized \(sinc(x)\) function whose roots are the non-zero integers as shown below
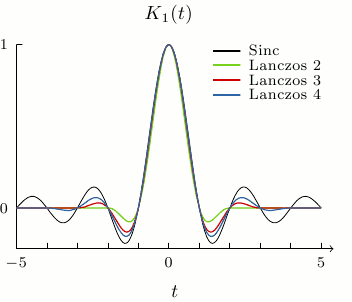
As you can see from the above image, the Lanczos kernel is smooth, continous and its magnitude dies of rapidly away from the origin. The discrete convolution of this kernel with the original signal (\(f(x)\)) data provides the new resampled/interpolated signal data (\(F(x)\)). In mathematical terms,
\[F(x) = \sum_{i=-a}^{a}f(i)L(x-i)\]In case of multidimensional signal (2D signal as in case of images), the interpolated signal is obtained as pointwise multiplication of the kernel
\[L(x,y) = L(x)L(y)\]OpenCV Implementation
In OpenCV, the Lanczos interpolation can be performed using the cv2.resize() function. Its python implementation is as follows
image_scale = cv2.resize(
image_input,
dsize=(no_cols_output, no_rows_input),
interpolation= cv2.INTER_LANCZOS4
)
where dsize is the size of the output image. In this function, the kernel size used is 8x8. We rescale the input image by a scale factor of 3. The interpolated smooth output image obtained is as follows.

As we can observe the image pixel density has been increased 3x times and the numbers now appear smoother in this modified image. Now when we apply the OCR on this smoothened image, we get back the correct text value of 166.3.
print(pytesseract.image_to_string(img_scale_bbox, config=custom_config))
# This produces the following output
# 166.3
Conclusion
In many scenarios, the real world datasets that we will come across are likely to have a wide range of issues. Poor resolution and noise is one of the most important among these problems. Using the appropriate interpolation to smoothen the image to improve its quality will help improve performance of OCR engines working on these images.